Reasoning that stays in latent space — on demand.
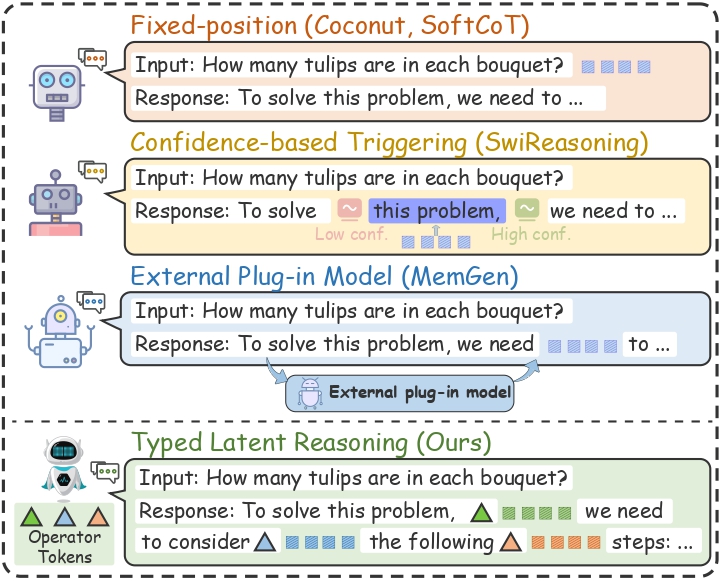
Chain-of-thought makes a model write out every intermediate step as text. That's redundant and slow, and it forces a rigid interface: the model must spell out its reasoning before it can answer, instead of computing internally when needed.
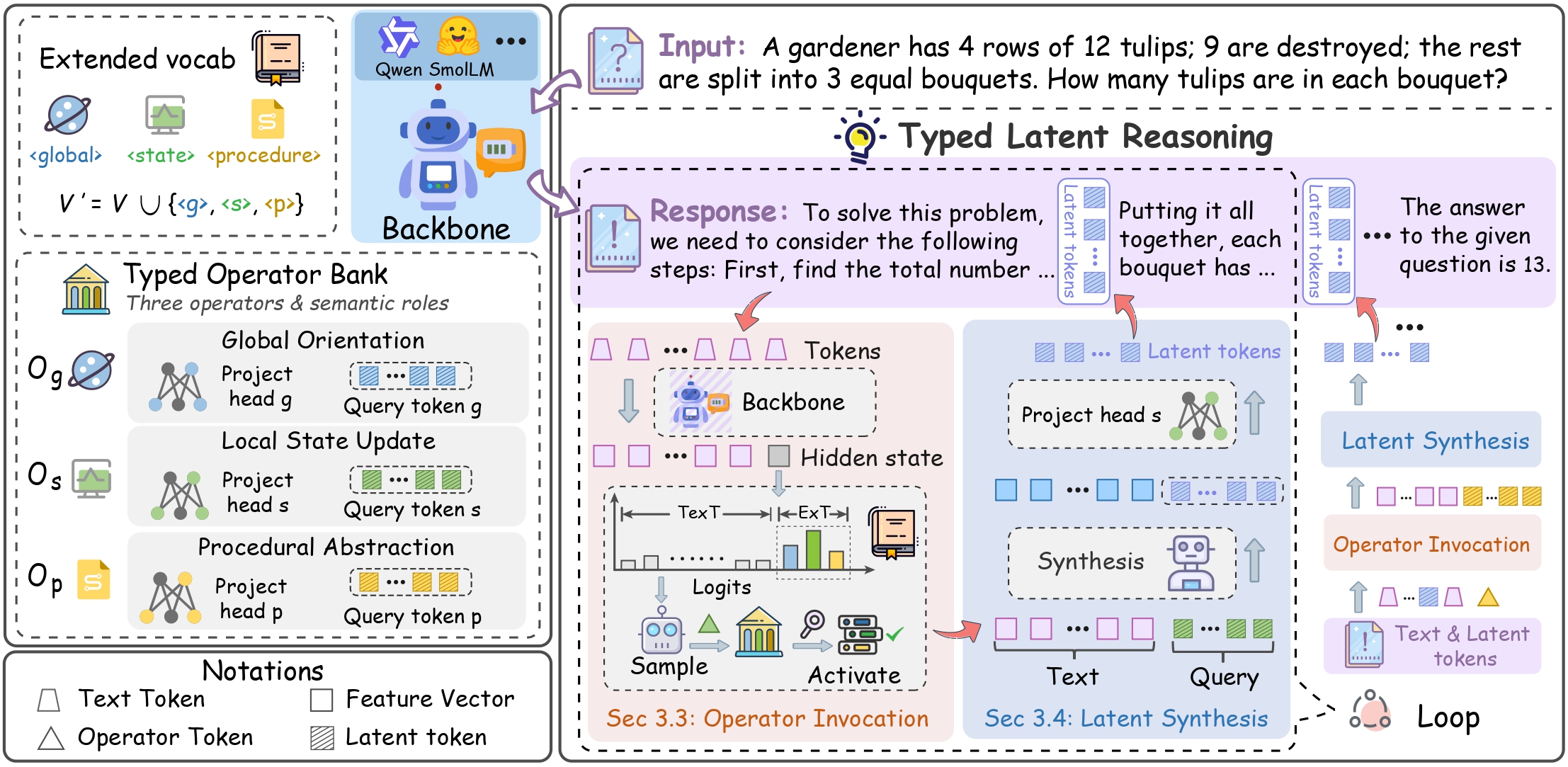
Tyler relaxes that interface. At each decoding step the model decides whether to emit a visible token or quietly switch to a typed latent operator that carries part of the computation in continuous representations. Prior latent-reasoning methods mostly focus on how to build latent tokens; Tyler instead reframes the problem as one of online control — when to think, what kind of computation to run, and how much budget to spend.
No fixed positions, no external trigger model. The choice between speaking and silently thinking competes inside a single next-action distribution, so the LLM itself stays in control.